-
Transformer공부 2021. 8. 9. 13:47
Minsuk Heo 허민석님의 유튜브 강의 "트랜스포머 (어텐션 이즈 올 유 니드)"를 듣고 정리한 내용입니다.
https://www.youtube.com/watch?v=mxGCEWOxfe8
* Transformer 가장 큰 특징
- Encoder / Decoder 기반
- RNN 사용 안함
- 병렬화
* 전통적인 RNN based Encoder / Decoder

- context vector는 고정된 크기를 가짐
* RNN based Encoder / Decoder with attention

- 고정된 크기의 context vector 사용하지 않음
- 대신 단어 하나씩 번역할 때마다 동적으로 encoder 출력값에 attention mechanism 수행하여 효율적으로 번역
- 긴 문장 번역 성능 개선
- 그러나 여전히 RNN cell 순차적으로 계산하여 느림
* How to remove RNN?

- RNN의 순차적인 계산을 단순한 행렬 곱으로 한번에 처리
- 한번의 연산으로 모든 중요 정보를 각 단어에 인코딩
- 기존 Encoder / Decoder concept는 그대로 간직 & RNN을 성공적으로 제거
- 학습 시간 단축
* How transformer knows word order?

- Positional encoding 이용
- Encoder 및 Decoder의 입력값마다 상대적인 위치 정보를 더해줌
- 실제 논문에서는 sine, cos 함수 이용 (-1 ~ 1 사이의 값)
- 학습 데이터보다 더 긴 문장이 들어와도 error 없이 상대적인 위치 정보 줄 수 있음
* Self Attention 연산

- Encoder에서 이뤄지는 attention 연산
- word embedding = 벡터
- 한 문장 = 행렬
- parameter matrix는 딥러닝 모델 학습 과정을 통해 최적화

- Query, Key, Value는 벡터 형태
- Key : 단어 자체의 embedding
- Value : 목적에 맞는 벡터
ex) (r, [255,0,0]) (g, [0,255,0])
r, g -> Key
[255,0,0], [0,255,0] -> Value

Query * Key = Attention Score -> Softmax * Value -> Sum
- Query : 현재 단어
- Key : 어떤 단어
- * : dot product
- Attention Score : 현재 단어와 어떤 단어의 상관 관계, 클수록 연관성 높음
- Softmax : Key 값에 해당하는 단어가 현재 단어에 어느정도 연관성이 있는가(%)
- Value : 각 Key 단어에 해당하는 Value
- Sum : 단순한 단어 I가 아닌 문장 속에서 단어 I가 지닌 전체적인 의미를 가진 벡터라고 간주
- 이 모든 attention 연산은 행렬곱으로 한방에 처리할 수 있음
* Multi Head Attention

- Transformer는 attention layer 8개를 병렬로 동시에 수행
- 기계 번역에 큰 도움이 됨

- 인간의 언어, 문장은 모호할 때가 상당히 많기 때문에 multi-head attentin을 사용해서 되도록 연관된 정보를 다른 관점에서 수집해서 보완
* Encoder 전반적인 구조

- 단어를 word embedding으로 전환
- Positional encoding 적용
- Multi head attention에 입력 & 결과 합치기
- 출력된 여러 결과값 이어붙여서 또다를 핸렬과 곱해져 결국 최초 word embedding과 동일한 차원을 갖는 벡터로 출력
- 각 벡터는 따로따로 FC layer에 들어가 입력과 동일한 size의 벡터 출력
* Residual Connection

- word embedding에 positional encoding 더해줬지만 역전파에 의해 많이 소실될 가능성 있음
- 이를 보완하기 위해 residual connection으로 한번 더 더해줌
- 덧셈이므로 역전파의 영향을 받지 않음
- residual connection 뒤에는 layer normalization 사용하여 학습의 효율도 증진시킴
- Encoder layer의 입력 벡터와 출력 벡터의 크기가 같음 -> Encoder layer를 여러개 이어붙일 수 있다
* Encoder 전반적인 구조
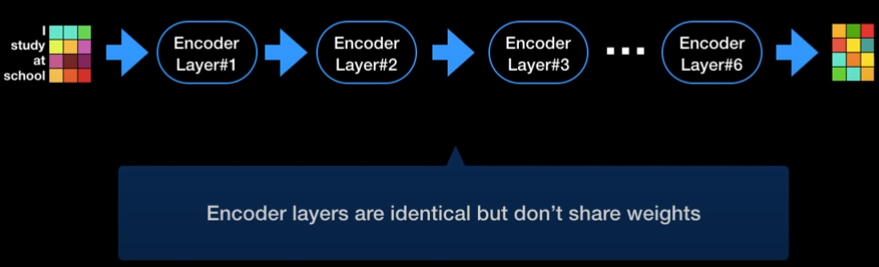
- Transformer는 Encoder layer를 6개 이어붙인 구조
- Encoder layer들은 weight를 공유하지 않고 따로 학습시킴

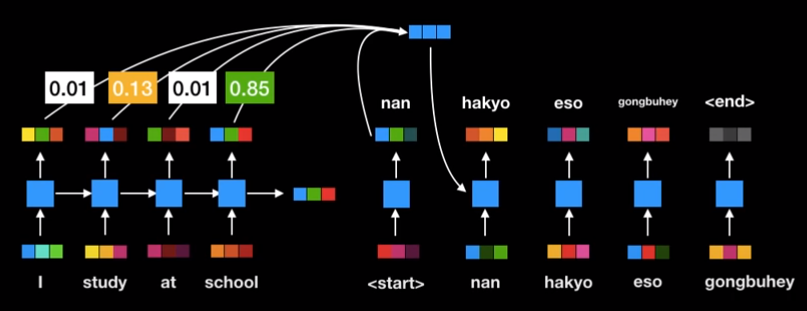
* Decoder

- 6개의 동일한 layer로 구성
- 최초 단어부터 끝 단어까지 순차적으로 단어 출력
- attention 병렬 처리 적극 활용
- 현재까지 출력된 단어들에 attention 적용
- Encoder 최종 출력값에도 attention 적용

- masked multi-head : 지금까지 출력된 값들에만 attention 적용
- encoder의 key, value 이용하지 않음
- self attention 개념(?)

- Multi head attention
- 현재 decoder의 입력값 = Query로 사용
- Encoder의 최종 출력값 = Key, Value로 사용
* 어떻게 벡터를 실제 단어로 출력?

- Linear : Sofrmax에 들어갈 logit 생성
- Softmax : 모델이 알고 있는 모든 단어에 대한 확률값 출력
- 확률이 가장 높은 단어가 다음 단어가 됨
* Label Smoothing

- Label smoothing을 사용해 model performace 업그레이드 시킴
- 보통 softmax 쓰면 label을 one-hot encoding으로 전환
- Transformer는 0에 가깝지만 0이 아닌, 1에 가깝지만 1이 아닌 값으로 표현
- 모델 학습시 모델이 너무 학습 데이터에 치중하여 학습하지 못하도록 보완
- 데이터가 noisy한 경우 큰 도움이 됨
ex) thank you -> 감사합니다 / 고맙습니다 둘 다 가능
