-
[논문 리뷰] Spatial-Temporal Multi-Cue Network for Continuous Sign Language Recognition수화 프로젝트 2021. 8. 13. 11:28

1. Introduction
- 본 논문은 continuous sign language recognition (CSLR)에 집중
CSLR : 일련의 sign을 일치하는 sign gloss sentence로 번역이 목적
- Sign language는 양 손의 shape, position, orientation, movement를 포함하는 manual element와
eye gaze, mouth shape, facial expression, body pose를 포함하는 non-manual element가 동시에 이뤄짐- 인간은 이러한 반응에서 복잡한 정보를 쉽게 처리하고 분석할 수 있음
- Deep neural network가 다중의 visual cue의 implicit collaboration을 발견하는 것은 어려움
- Multi-cue information을 연구하기 위한 다양한 방법들 제안되었으나 2가지 한계점 존재
1) external tools impede the end-to-end learning on the differentiable structure of neural networks
2) off-the-shelf tool과 multi-stream networks는 같은 지역에서 반복적인 특징을 잡아내어 video-based translation task에서 매우 비싼 계산 비용 초래함
- Multiple diverse cues with unequal feature importance에서 strong feature와 weak feature 사이의 시너지를 완전히 탐구하는 것 어려움
- 특히 neural network은 빠른 수렴을 위해 strong feature에만 집중하는 경향이 있음
- 본 논문은 새로운 spatial-temporal multi-cue (STMC) framework 제안
2. Related Work
- CSLR system : video representation + sequence learning
* Video representation
- hand-crafted features
- deep learning based methods
- combine 2D-CNN with temporal layers for spatial-temporal representation
- 3D-CNN
* Sequence learning
- video sequence와 sign gloss sequence 사이의 correspondense를 학습하는 것
- integrate 2D-CNNs with hidden markov models (HMM)
- connectionist temporal classification (CTC)
- attention-based encoder-decoder model
- Sign language의 multiple cue : multi-modality + multi-semantic
* Multi-modality
- 3D space information을 모으기 위해 physical sensor 이용
- multi-modality fusion of RGB and optical flow
* Multi-semantic
- hand-crafted features
- feature sequence of hand patches captured by a tracker is fused with feature sequence of full-frames
- weak mouth labels and weak hand labels
- 본 논문 : end-to-end differentiable network for multi-cue fusion with joint optimization
3. Proposed Approach
3.1. Framework Overview

Figure 1. An overview of the proposed STMC framework - video가 주어졌을 때 CSLR task의 목적은 일치하는 sign gloss sequence를 예측하는 것
- 3개의 key module로 구성
1) Spatial Representation : SMC module
- full-frame, hand, face, pose를 포함한 multiple cue의 spatial feature 생성
2) Temporal Modelling : TMC module
- 다른 time step과 ime scale에서 intra-cue feature와 inter-cue feature의 temporal correlation을 포착
3) Sequence Learning : BLSTM, CTC
- Bidirextional Long-Short Term Memory encoder (BLSTM)과 connectionist temporal classification (CTC)
- sequence learning과 inference
3.2. Spatial Multi-Cue Representation

Figure 2. The SMC Module - full-frame, hand, face, pose를 포함한 multiple cue의 spatial feature 생성하기 위해 2D-CNN 필요
- 본 논문에서는 backbone network로 VGG-11 model 채택
* Pose Estimation
- VGG-11의 7번째 convolutional layer 다음에 2개의 deconvolutional layer 추가됨
- Output은 K predicted heat map을 생성하기 위해 point-wise convolutional layer에 들어감 (K=7로 설정)
- In each heat map, the position of its corresponding keypoint is expected to show the highest response value
- Keypoint prediction을 미분가능하게 만들기 위해 heat map에 soft-argmax layer가 적용됨
- Spatial softmax function :

h_i,j,k : position (i, j)에서 heat map h_k의 value
p_i,j,k : position (i, j)에서 keypoint k의 확률
- 전체 확률 map에서 x-axis, y-axis를 따라서 기댓값 계산 :

* Patch Cropping
- CSLR에서 eye gaze, facial expression. mouth shape, hand shape, orientation of hand 등 디테일한 visual cue 중요
- 제안 모델에서는 얼굴과 양 손의 center point로써 코와 양 손목의 위치를 예측
- Patch들은 VGG-11의 4번째 convolutional layer의 output로부터 crop됨
- Cropping size는 양 손은 24 x 24, 얼굴은 16 x 16으로 고정
* Feature Generation
- K keypoint가 에측된 후 2K dimension에서 1D-vector로 flatten
- Pose cue의 feature vector를 얻기 위해 2개의 fully-connected (FC) layers with ReLU를 통과
- Face와 양 손의 feature map은 crop되고 각각 7개의 convolutional layer를 통과
- Sign gesture는 양 손의 협력에 가장 크게 의존하므로 양 손에 weight-sharing convolutional layer를 사용
- 결과들은 channel-dimension을 따라 concatenate
- 다른 cue들의 feeature vector를 구성하기 위해 spatial dimension으로 모든 feature map을 global average pooling
- Spatial multi-cue (SMC) module :
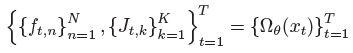
J_t,k : position of keypoint k at the t-th frame
f_t,n : feature vector of visual cue n at the t-th frame
- N=4 : visual cues of full-frame, hand, face, pose
3.3. Temporal Multi-Cue Modelling

Figure 3. The TMC Module - Temporal multi-cue (TMC) module은 2가지 측면의 spatiotemporal information을 통합 : intra-cue & inter-cue
- Intra-cue path : 각 visual cue의 독특한 feature를 포착
- Inter-cue path : 다른 time scale에서 다른 cue들로부터 fused feature의 combination을 학습
- TMC block to model the operatopms between the two paths :

o : feature matrix of the inter-cue path
f : feature matrix of the intra-cue path, concatenation of vectors from different cues along channel-dimension
* Intra-Cue Path
- to provide unique features of different cues at different time scales
- temporal transformation inside each cue :

K : kernel of a temporal convolution
* Inter-Cue Path
- to perform the temporal transformation on the inter-cue feature from the previous block and fuse information from the intra-cue path

K : point-wise temporal convolution, It serves as a project matrix between the two paths
- 각 block 다음에 temporal max-pooling with stride 2 and kernel size 2 수행
- TMC module에서 2 block 사용
- point-wise 제외하고 모든 temporal convolution의 kernel size k=5
- 각 path의 output channels 수 C=1024
3.4. Sequence Learning and Inference
- 제안한 SMC와 TMC module을 통해 inter-cue feature sequence와 intra-cue feature sequence를 생성
- how to utilize these two feature sequences to accomplish the sequence learning and inference
* BLSTM Encoder
-
* Connectionist temporal classification
-
* Joint Loss Optimization
-
4. Experiments
4.1. Dataset and Evaluation

Figure 4. The effect of weight parameter α in Eq. 14 4.2. Implementation Details

Figure 5. A qualitative result of different cues with estimated poses (zoom in) from Dev set (D: delete, I: insert, S: substitute) 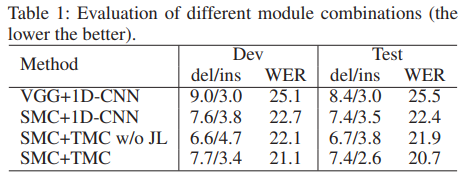

4.3. Framework Effectiveness Study

4.4. State-of-the-art Comaprision



5. Conclusion
- End-to-end fashion에서 visual cue들의 spatial- temporal correlation을 학습하는 것을 목적으로 하는 새로운
spatial-temporal multi-cue (STMC) framework 제안- Spatial multi-cue module은 spatial multi-cue feature를 decompose하기 위해 self-contained pose estimation branch로 디자인
- Temporal multi-cue module은 각 cue의 uniquness 를 보존하면서 동시에 다른 cue들 사이의 시너지를 탐구하기 위해 intra-cue와 inter-cue path로 구성
- Joint optimization strategy가 multi-cue sequence learning을 위해 제안됨
- 3개의 large-scale CSLR dataset에서 진행된 광범위한 실험이 STMC framework의 우수성을 증명함
'수화 프로젝트' 카테고리의 다른 글
Neural Sign Language Translation based on Human Keypoint Estimation (0) 2021.09.13