-
WBM Classification project프로젝트 2021. 7. 1. 14:08
1. 연구 배경
반도체 공정은 wafer 단위로 생산이 되며, 모든 공정이 끝난 후 wafer 내 칩을 하나씩 자르면 반도체 칩이 된다. Wafer bin map(WBM)이란 wafer 내 각 칩 별 정상/불량 판정 결과를 2차원 이미지 형태로 표현한 것이다.

그림 1. 반도체 Wafer bin map 예시 특정 공정 및 설비에서 이상 발생 시 해당 공정 및 설비를 거친 wafer들은 유사한 WBM 불량 패턴을 보인다. 예를 들어 ‘Random’ 불량 패턴의 경우 제조 환경의 먼지 입자 문제로 인해 주로 발생하며, ‘Edge-ring’ 불량 패턴의 경우 플라즈마 에칭 속도 불균일 문제로 인해 주로 발생한다. ‘Scratch’ 불량 패턴의 경우 CMP 공정에서 또는 이동 중 wafer handling 문제로 인해 주로 발생한다. 즉, WBM 불량 패턴을 자동적으로 분류할 수 있다면 분류 결과에 따라 불량을 야기한 특정 공정 및 설비를 신속하게 추적하여 근본 원인을 빠르게 해결할 수 있다.

그림 2. WBM 불량 패턴 예시 그림 2 출처 : T. Nakazawa and D. V. Kulkarni, "Wafer Map Defect Pattern Classification and Image Retrieval Using Convolutional Neural Network," in IEEE Transactions on Semiconductor Manufacturing, vol. 31
2. 연구 방법론
본 연구는 2단계로 나누어 진행하였다.
2-1. 1-stage 모델
첫번째 단계에서는 불량 패턴을 구분하지 않고, 데이터의 정상/불량을 판별하는 이진 분류 문제를 해결하기 위해 Convolution Neural Network(CNN) 모델을 이용하였다. CNN은 지역 정보(region feature)를 학습시키기 위한 신경망 모델로 Yann LeCun 교수가 1998년에 제안한 모델이다. CNN은 Region feature를 뽑아 내기 위한 Convolution Layer와 feature dimension을 위한 Pooling Layer, 최종적인 분류를 위한 Fully Connected Layer로 구성된다.
본 연구에서 사용한 CNN 구조는 그림 3과 같다. 2개의 Convolution layer, 2개의 Pooling layer와 1개의 Fully Connected Layer로 구성되어 있다. Batch size는 32로 설정하였다. Activation function으로는 ReLU 함수를 이용하였고 Max Pooling을 이용하였다. 과적합을 방지하기 위해 Dropout(probability=0.2)와 Xavier uniform weight initialization을 추가하였다. 모델의 최종 output은 Fully Connected Layer의 output에 sigmoid 함수를 적용한 것이다. Loss function으로는 binary cross entropy loss(BCELoss), optimizer로는 Adam을 적용하였다.
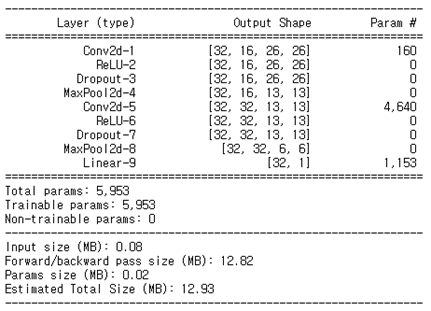
그림 3. 1-stage CNN 모델 구조 2-2. 2-stage 모델
두번째 단계에서는 불량 데이터에서 불량 패턴을 분류하는 다중 분류 문제를 해결하기 위해 Siamese Network 모델을 이용하였다. Siamese Network 모델의 목표는 두 개의 입력 데이터가 동일한지 여부를 판단하는 것이다. 학습 과정에서는 두 개의 입력 데이터를 쌍으로 받아 거리(비유사도)를 계산한 후, 같은 label에 속하면 거리가 짧아지고 다른 label에 속하면 거리가 멀어지도록 학습한다.
Siamese Network의 학습 과정 구조는 그림 4와 같다. Siamese Network은 입력은 구분되고 가중치는 공유하는 2개의 쌍둥이 CNN으로 구성된다. 학습 데이터를 두 개씩 짝지어 쌍둥이 CNN에 입력하여 두 개의 특징 벡터(embedding)를 추출하고, 특징 벡터 사이의 거리를 계산한다. 학습 과정에서는 두 입력 데이터가 같은 label에 속하면 거리가 짧아지고, 다른 label에 속하면 거리가 멀어지도록 설계된 Loss function을 통해 반복적으로 학습한다.

그림 4. Siamese Network 학습 구조 Siamese Network의 테스트 과정 구조는 그림 5와 같다. 학습 과정을 반복하며 같은 label에 속하는 데이터와 차이는 최소화하고 다른 label에 속하는 데이터와 차이는 최대화하는 특징 벡터가 추출된다. 같은 label에 속하는 특징 벡터의 평균을 계산하여 각 label을 대표하는 특징 벡터를 생성한다. 테스트 데이터를 학습된 CNN에 넣어 테스트 데이터의 특징 벡터를 추출한 후 각 label의 대표 특징 벡터와 거리를 계산한다. 거리가 가장 짧은 특징 벡터와 같은 label로 분류한다.

그림 5. Siamese Network 테스트 구조 본 연구에서 사용한 Siamese Network의 구조는 그림 6과 같다. 3개의 Convolution layer, 1개의 Pooling layer와 1개의 Fully Connected Layer로 구성되어 있다. Batch size는 32로 설정하였다. Activation function으로는 ReLU 함수를 이용하였고 Max Pooling을 이용하였다. 과적합을 방지하기 위해 Dropout(probability=0.5)를 추가하였다. 모델의 최종 output은 Fully Connected Layer의 output인 16차원의 특징 벡터이다. Loss function으로는 Contrastive Loss를, optimizer로는 Adam을 적용하였다.


그림 6. 2-stage Siamese Network 구조 3. 실험 및 결과
3-1. 데이터 셋
본 연구에서는 실제 반도체 공정에서 얻어진 811,456개의 WBM 데이터로 구성된 Kaggle 오픈 데이터셋, WM-811K를 이용하였다. 해당 데이터셋은 이미지 데이터 사이즈가 다양하고 label이 기록되지 않은 데이터가 다수 존재한다. 따라서 본 연구를 위해서는 26x26 사이즈의 label이 있는 14,366개의 데이터를 이용하여 진행하였다. 데이터셋은 정상 데이터와 그림 7을 비롯한 8개의 불량 패턴 데이터로 구성되어 있다. 정상 데이터는 13,489개이며 불량 패턴 별 데이터 수는 표 1과 같다.

그림 7. WM-811K WBM 데이터 예시 
표 1. 불량 패턴 별 데이터 수 3-2. 1-stage 데이터 전처리
불량 패턴을 구분하지 않고, 데이터의 정상/불량을 판별하는 이진 분류 문제를 해결하기 위해 불량 데이터는 패턴 구별 없이 모두 label을 1로 설정하고, 정상 데이터는 label을 0으로 설정하였다. 불량 패턴을 구별하지 않아도 정상 데이터는 13,489개, 불량 데이터는 877개로 label 불균형 문제가 심각하다. Label 불균형 문제를 해결하기 위해 정상 데이터는 랜덤하게 1000개로 under sampling을 진행하였다. 전체 데이터 중 80%는 학습 데이터, 20%는 테스트 데이터로 사용하였다.
3-3. 2-stage 데이터 전처리
불량 데이터에서 불량 패턴을 분류하는 다중 분류 문제를 해결하기 위해 2종류의 서브 데이터셋을 만들어 결과를 비교했다. 첫번째 서브 데이터셋은 정상 데이터와 데이터가 1개뿐인 ‘Donut’ 데이터를 제외한 나머지 7종류의 불량 패턴을 가진 데이터로 구성하였다. 두번째 서브 데이터셋은 데이터수가 많은 ‘Center’, ‘Edge-Loc’, ‘Loc’, 총 3종류의 불량 패턴을 가진 데이터로 구성하였다. 두 경우 모두 전체 데이터 중 80%는 학습 데이터, 20%는 테스트 데이터로 사용하였다.
Siamese Network는 두 개의 입력 데이터를 받아 두 입력 데이터의 특징 벡터 사이의 거리를 구하는 알고리즘이기 때문에 입력 데이터를 랜덤하게 두 개씩 짝짓고, 두 입력 데이터의 label이 같으면 0, 다르면 1로 새롭게 설정하였다. 즉, 이미지 데이터 2개와 두 이미지 데이터의 label 동일여부를 나타내는 새로운 label 데이터 1개로 구성된 총 2000개의 데이터셋을 만들어 사용하였다.
3-4. 1-stage 실험 결과
그림 3과 같은 구조를 가진 CNN 모델로 데이터의 정상/불량을 판별하는 이진 분류 문제를 해결 한 결과, epoch에 따른 train loss/test loss 그래프는 그림 8과 같다. Epoch에 따른 train accuracy/test accuracy 그래프는 그림 9와 같다. Train loss는 epoch이 증가할수록 꾸준하게 감소하 며 수렴하지만, test loss는 epoch이 대략 100일 때 최소이며, 그 뒤에는 진동하며 증가하는 경향 을 보인다. Epoch이 500일 때 train loss는 0.0004, test loss는 0.0102이다. Accuracy는 마지막 sigmoid 함수를 통과한 최종 output이 0.5보다 크면 불량으로, 0.5보다 낮으면 정상으로 예측한 결과와 실제 label을 비교하여 계산하였다. Train accuracy는 99.67%에서 수렴하지만 test accuracy 는 train accuracy에 비해 다소 낮은 92.29%에서 수렴한다. 이는 1-stage CNN 모델이 학습 데이터 에 다소 과적합 되었음을 의미한다.

그림 8. 1-stage train loss / test loss 그래프 
그림 9. 1-stage train accuracy / test accuracy 그래프 3-5. 2-stage 실험 결과
3-5-1. 7종류 불량 패턴 실험 결과
그림 6과 같은 구조를 가진 Siamese Network 모델로 7종류의 불량 패턴을 판별하는 다중 분류 문제를 해결한 결과, epoch에 따른 train loss 그래프는 그림 10과 같다. Train loss는 epoch이 증가할수록 꾸준하게 감소하며 0.004 정도에 수렴한다.

그림 10. 2-stage 7 faulty type train loss 그래프 Siamese Network로 학습을 하기 전과 후의 특징 벡터를 추출하여 t-SNE로 2차원 공간에 매핑하여 시각화하면 그림 11과 같다. 학습 전에는 그림 11의 왼쪽 그림과 같이 모든 label의 데이터가 랜덤하게 섞여 분포되어 있지만 학습 후에는 그림 11의 오른쪽 그림과 같이 label 별로 특징 벡터 공간에 가깝게 위치하며 클러스터를 형성하는 것을 확인할 수 있다.

그림 11. 학습 전후 7 faulty type 특징 벡터 t-SNE 시각화 3-5-2. 3종류 불량 패턴 실험 결과
그림 6과 같은 구조를 가진 Siamese Network 모델로 3종류의 불량 패턴을 판별하는 다중 분류 문제를 해결한 결과, epoch에 따른 train loss 그래프는 그림 12과 같다. Train loss는 epoch이 증가할수록 꾸준하게 감소하며 0.004 정도에 수렴한다.

그림 12. 2-stage 3 faulty type train loss 그래프 Siamese Network로 학습을 하기 전과 후의 특징 벡터를 추출하여 t-SNE로 2차원 공간에 매핑하여 시각화하면 그림 13과 같다. 학습 전에는 그림 13의 왼쪽 그림과 같이 모든 label의 데이터가 랜덤하게 섞여 분포되어 있지만 학습 후에는 그림 13의 오른쪽 그림과 같이 label 별로 특징 벡터 공간에 가깝게 위치하며 뚜렷한 클러스터를 형성하는 것을 확인할 수 있다. 7종류 불량 패턴을 모두 고려한 그림 11보다 label 수가 적어 특징 벡터 클러스터가 더 명확하게 구분되는 것을 확인할 수 있다.

그림 13. 학습 전후 3 faulty type 특징 벡터 t-SNE 시각화 3-5-3. 7종류/3종류 불량 패턴 실험 결과 비교
Siamese Network의 학습이 끝난 후 같은 label끼리의 특징 벡터의 평균을 구해 각 label의 대표 특징 벡터를 계산하였다. Test data를 학습된 Siamese Network에 통과시켜 테스트 데이터의 특징 벡터를 구하고, 각 label의 대표 특징 벡터와 거리를 계산하여 거리가 가장 짧은 대표 특징 벡터와 같은 label로 분류하였다. 분류 결과와 실제 label을 비교하여 test accuracy를 계산하였다. 7종류의 불량 패턴과 3종류의 불량 패턴을 이용한 경우 각각의 test accuracy는 표 2와 같다. 7종류의 불량 패턴을 이용한 경우보다 3종류의 불량 패턴을 이용한 경우의 test accuracy가 더 높게 나타난 것을 확인할 수 있다.

표 2. 7 faulty type / 3 faulty type test accuracy 4. 결론
본 연구에서는 WBM 데이터의 불량 패턴을 분류하기 위해 2 단계로 나누어 진행하였다. 첫번 째 단계에서는 데이터의 정상/불량을 판별하는 이진 분류 문제를 해결하기 위해 CNN 모델을 이 용하였다. 그 결과 train accuracy는 99.67%, test accuracy는 92.29%로 다소 학습 데이터에 과적합 된 경향이 있지만, 높은 분류 성능을 보인다. 두번째 단계에서는 데이터의 불량 패턴을 판별하는 다중 분류 문제를 해결하기 위해 Siamese Network 모델을 이용하여 7종류의 불량 패턴과 3종류 의 불량 패턴을 고려한 경우의 실험 결과를 비교하였다. 7종류의 불량 패턴을 고려한 경우 test accuracy는 61.36%, 3종류의 불량 패턴을 고려한 경우 test accuracy는 75.91%로 데이터 수가 많 은 3종류의 불량 패턴을 고려한 경우의 성능이 더 높게 나타났다. Siamese Network에서 생성된 특징 벡터를 추출하여 2차원의 특징 벡터 공간에 t-SNE를 통해 매핑하여 시각화한 결과 두 경우 모두 학습 전에 비해 학습 후 같은 label을 가진 특징 벡터끼리 가까이 위치하며 클러스터를 형 성하는 것을 시각적으로 확인할 수 있다. 따라서 Siamese Network가 feature extraction 모델로 사 용되기에도 적절할 것으로 기대된다. 향후 CNN, Siamese Network 구조를 최적화한다면 모델 성 능을 더 극대화 시킬 수 있을 것으로 기대된다.
- 2021-1학기 CSE5851-01 딥러닝과 데이터과학 수업에서 Final report로 제출한 내용
- 너무 급하게 코드 짜고 레포트 쓰느라 빈약하고 미흡한 내용 및 결과가 다수 포함되어 있을듯..
- 언젠가 다시 제대로 디벨롭 해봐야지....... ㅎ_ㅎ